Treat your flaky tests like production bugs
by Paweł Świątkowski
30 Apr 2021
Flaky tests are a bane of every larger test suite out there. At first they show up very rarely. Once in a hundred CI runs you need to manually re-run it to have the test suite pass. It’s not that bad, so you just do it. Then more of them appear. And before you realize, you have more failed runs that successful ones. The CI process has lost its value and everyone is frustrated.
If you use continuous delivery, when deploys are automatically done from some specific branch after tests pass, flaky tests are simply disastrous. But even if you don’t have this setup, they damage your trust in the tests and hurt your delivery process. Having the test suite green before merge will soon become a not-really-mandatory requirement (because how are you supposed to deliver this hotfix to the production when you have to re-run your 20 minutes tests five times before merge?). You will also inevitably start to treat every tests failure as a flake, making you miss legitimate failures.
This is why your team should make its priority to not have flaky tests. Unfortunately not many team do that, settling on “yeah, it works most of the time”. I had a luck to work in a team that treated flaky tests seriously - and even without a written contract about it! It worked pretty well, so I want to share how the process of dealing with such situation looked like.
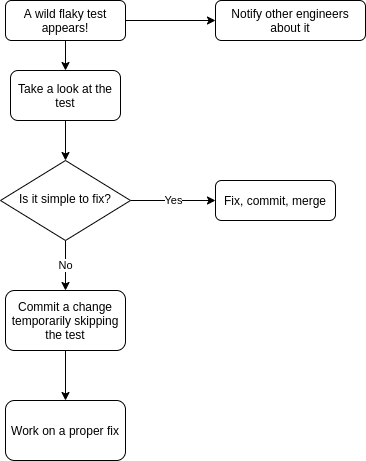
- When someone encountered a flaky test, instead of ignoring it and just re-running the suite, it was reported to the engineering channel on Slack.
- Than the person who found it took a brief look at the test in question. Sometimes it was a quick win, for example there wasn’t any ordering in the database query but assertion assumed that the records are sorted by id. If so, the test was fixed, pushed and merged.
- If not, however, the person announced that she is working on this flaky test. No one had any objections because everyone knew it was important, just as dealing with a production bug is. However, to unblock the pipeline, the first step was usually to skip the test in question, push and merge, so everyone else can work uninterrupted.
- Now the person responsible for fixing the test (BTW it may be a different person from the one who spotted the flakiness) is trying to understand what happened and how to fix it. There are many possible outcomes here - the test might be repaired but it also can be deleted it it’s flaky by it’s nature (for example testing something random). Or it can be rewritten because we cannot find why it fails sometimes but there’s some other way to tests this thing it tests. Important thing is that it’s not an option to “just leave it, it shouldn’t fail that often”.
It worked very well and not only helped us have relatively flaky-free tests but also encouraged people to take responsibility for the common codebase. The first reflex was to try to fix it, not to try to blame someone for breaking it. I highly recommend every team to try it.